Penulis: Muhammad Ilham Ashiddiq Tresnawan, S.T., B.Sc., M.Sc.
Sumber: ai.plainenglish.io
Di era perkembangan teknologi digital saat ini, pemanfaatan Machine Learning semakin banyak digunakan untuk membantu proses analisis data dalam berbagai bidang. Salah satu metode yang cukup populer dalam pengolahan data adalah K-Means Clustering. Algoritma ini digunakan untuk mengelompokkan data berdasarkan kemiripan karakteristik sehingga data yang memiliki pola serupa akan berada dalam satu kelompok yang sama.
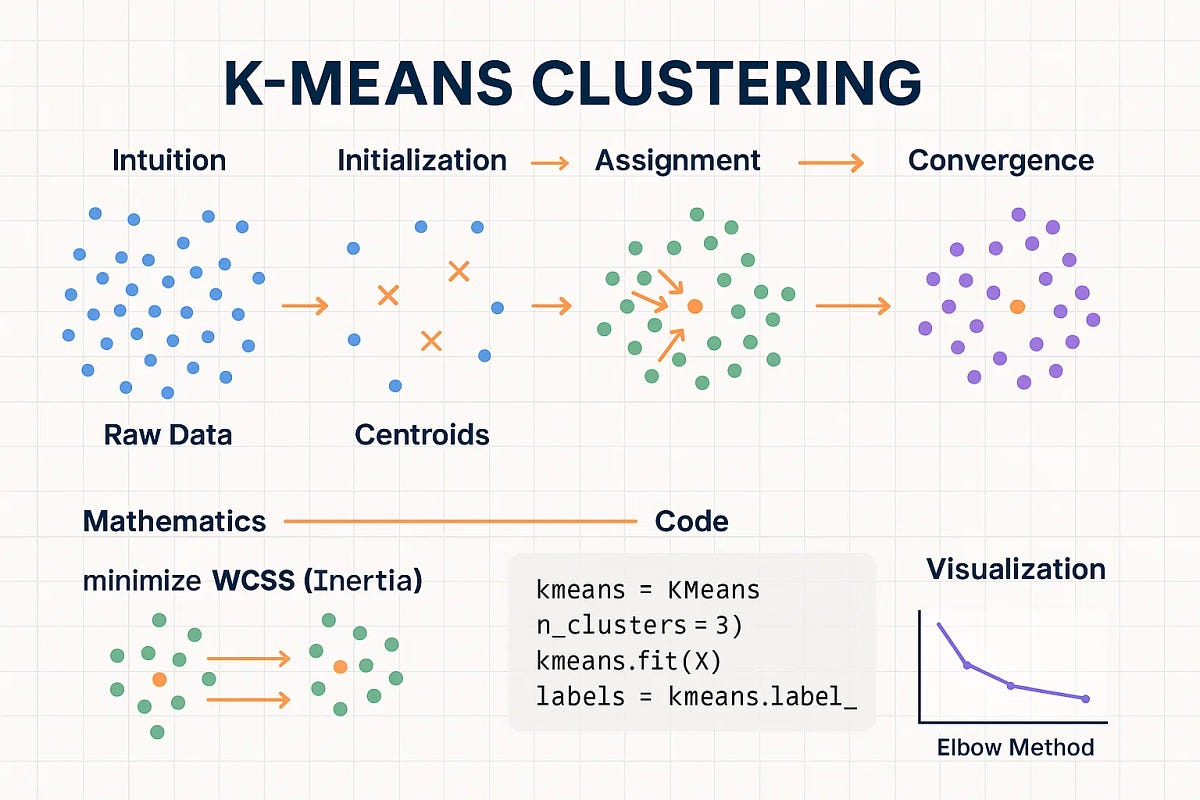
K-Means Clustering merupakan salah satu metode dalam Unsupervised Learning, yaitu pembelajaran mesin yang bekerja tanpa menggunakan label data. Sistem akan mempelajari pola dan hubungan antar data secara otomatis untuk membentuk beberapa kelompok atau cluster. Metode ini sering digunakan dalam analisis data karena memiliki proses yang relatif sederhana dan efisien dalam menangani data dalam jumlah besar.
Dalam proses kerjanya, algoritma K-Means akan membagi data ke dalam beberapa kelompok berdasarkan titik pusat yang disebut centroid. Sistem akan menghitung jarak antar data dan menentukan kelompok yang paling sesuai berdasarkan kedekatan karakteristik data tersebut. Setelah itu, centroid akan diperbarui secara berulang hingga menghasilkan pengelompokan data yang optimal.
Salah satu penerapan K-Means Clustering yang paling umum adalah pada analisis pelanggan dalam dunia bisnis dan pemasaran digital. Perusahaan dapat mengelompokkan pelanggan berdasarkan pola belanja, usia, minat, lokasi, maupun kebiasaan penggunaan layanan digital. Dengan pengelompokan tersebut, perusahaan dapat menentukan strategi pemasaran yang lebih tepat sasaran dan efektif.
Selain digunakan dalam bidang bisnis, K-Means Clustering juga banyak diterapkan dalam berbagai sektor lainnya, seperti kesehatan, pendidikan, keamanan siber, hingga media sosial. Dalam bidang kesehatan, algoritma ini dapat membantu mengelompokkan data pasien berdasarkan gejala atau riwayat penyakit tertentu. Pada keamanan siber, metode ini digunakan untuk mendeteksi pola aktivitas jaringan yang mencurigakan atau tidak normal.
Dalam dunia teknologi informasi, pengelompokan data menggunakan K-Means membantu proses analisis menjadi lebih mudah dipahami. Data yang awalnya besar dan kompleks dapat dibagi menjadi beberapa kelompok dengan karakteristik tertentu sehingga memudahkan proses pengambilan keputusan berbasis data.
Keunggulan utama dari algoritma K-Means Clustering adalah prosesnya yang cepat, sederhana, dan mudah diimplementasikan. Algoritma ini juga mampu menangani data dalam jumlah besar dengan performa yang cukup baik. Oleh karena itu, metode ini sering digunakan sebagai dasar dalam berbagai penelitian maupun pengembangan sistem berbasis data.
Meskipun demikian, K-Means Clustering juga memiliki beberapa keterbatasan. Salah satunya adalah pengguna harus menentukan jumlah kelompok (cluster) di awal proses. Selain itu, hasil pengelompokan dapat dipengaruhi oleh posisi awal centroid dan jenis data yang digunakan. Oleh karena itu, diperlukan proses analisis dan evaluasi agar hasil clustering menjadi lebih optimal.
Saat ini, penggunaan K-Means Clustering menjadi salah satu bagian penting dalam perkembangan teknologi Artificial Intelligence (AI) dan Data Science. Banyak perusahaan dan institusi memanfaatkan algoritma ini untuk membantu proses analisis data secara otomatis dan efisien.
Secara keseluruhan, K-Means Clustering merupakan metode pengelompokan data pada Machine Learning yang digunakan untuk menemukan pola dan membagi data ke dalam beberapa kelompok berdasarkan kemiripan karakteristik. Dengan penerapan yang tepat, algoritma ini dapat membantu proses analisis data menjadi lebih efektif, terstruktur, dan mendukung pengambilan keputusan secara lebih akurat.
🔍 Tertarik mendalami Teknologi Informasi? Cek Program Studi Teknologi Informasi Universitas Internasional Batam dan pilih peminatanmu: Cloud Engineering, Smart Systems, atau Cyber Intelligence. Segera daftarkan dirimu di Pendaftaran Program Sarjana Teknologi Informasi.
Editor: Ambarwulan, S.T.
Referensi
- Han, J., Kamber, M., & Pei, J. Data Mining: Concepts and Techniques. Morgan Kaufmann.
- Bishop, C. M. Pattern Recognition and Machine Learning. Springer.
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow. O’Reilly Media.
- Alpaydin, E. Introduction to Machine Learning. MIT Press.
- Murphy, K. P. Machine Learning: A Probabilistic Perspective. MIT Press.
- Russell, S., & Norvig, P. Artificial Intelligence: A Modern Approach. Pearson.
- Jain, A. K. Data Clustering: 50 Years Beyond K-Means. Pattern Recognition Letters.
- Witten, I. H., Frank, E., & Hall, M. A. Data Mining: Practical Machine Learning Tools and Techniques. Morgan Kaufmann.
- IBM. “What is Clustering in Machine Learning?”
IBM Clustering in Machine Learning - Google Developers. “Introduction to Machine Learning.”
Google Developers Machine Learning Guide - Scikit-Learn Documentation. “K-Means Clustering.”
Scikit-Learn K-Means Documentation - AWS Machine Learning. “Clustering Algorithms.”
AWS Clustering Algorithms Overview - Microsoft Azure. “Machine Learning Algorithms.”
Microsoft Azure Machine Learning Guide - Oracle AI and Analytics.
Oracle AI and Analytics Overview - Coursera. “Machine Learning Clustering Methods.”
Coursera Clustering Courses



